Looker
There are 2 sources that provide integration with Looker
| Source Module | Documentation |
| This plugin extracts the following:
note To get complete Looker metadata integration (including Looker views and lineage to the underlying warehouse tables), you must ALSO use the |
| This plugin extracts the following:
note To get complete Looker metadata integration (including Looker dashboards and charts and lineage to the underlying Looker views, you must ALSO use the |
Module looker
Important Capabilities
| Capability | Status | Notes |
|---|---|---|
| Column-level Lineage | ✅ | Enabled by default, configured using extract_column_level_lineage |
| Dataset Usage | ✅ | Enabled by default, configured using extract_usage_history |
| Descriptions | ✅ | Enabled by default |
| Detect Deleted Entities | ✅ | Optionally enabled via stateful_ingestion.remove_stale_metadata |
| Extract Ownership | ✅ | Enabled by default, configured using extract_owners |
| Platform Instance | ✅ | Use the platform_instance field |
| Table-Level Lineage | ✅ | Supported by default |
This plugin extracts the following:
- Looker dashboards, dashboard elements (charts) and explores
- Names, descriptions, URLs, chart types, input explores for the charts
- Schemas and input views for explores
- Owners of dashboards
To get complete Looker metadata integration (including Looker views and lineage to the underlying warehouse tables), you must ALSO use the lookml module.
Prerequisites
Set up the right permissions
You need to provide the following permissions for ingestion to work correctly.
access_data
explore
manage_models
see_datagroups
see_lookml
see_lookml_dashboards
see_looks
see_pdts
see_queries
see_schedules
see_sql
see_system_activity
see_user_dashboards
see_users
Here is an example permission set after configuration.

Get an API key
You need to get an API key for the account with the above privileges to perform ingestion. See the Looker authentication docs for the steps to create a client ID and secret.
Ingestion through UI
The following video shows you how to get started with ingesting Looker metadata through the UI.
You will need to run lookml ingestion through the CLI after you have ingested Looker metadata through the UI. Otherwise you will not be able to see Looker Views and their lineage to your warehouse tables.
CLI based Ingestion
Install the Plugin
pip install 'acryl-datahub[looker]'
Starter Recipe
Check out the following recipe to get started with ingestion! See below for full configuration options.
For general pointers on writing and running a recipe, see our main recipe guide.
source:
type: "looker"
config:
# Coordinates
base_url: "https://<company>.cloud.looker.com"
# Credentials
client_id: ${LOOKER_CLIENT_ID}
client_secret: ${LOOKER_CLIENT_SECRET}
# sink configs
Config Details
- Options
- Schema
Note that a . is used to denote nested fields in the YAML recipe.
| Field | Description |
|---|---|
base_url ✅ string | Url to your Looker instance: https://company.looker.com:19999 or https://looker.company.com, or similar. Used for making API calls to Looker and constructing clickable dashboard and chart urls. |
client_id ✅ string | Looker API client id. |
client_secret ✅ string | Looker API client secret. |
emit_used_explores_only boolean | When enabled, only explores that are used by a Dashboard/Look will be ingested. Default: True |
external_base_url string | Optional URL to use when constructing external URLs to Looker if the base_url is not the correct one to use. For example, https://looker-public.company.com. If not provided, the external base URL will default to base_url. |
extract_column_level_lineage boolean | When enabled, extracts column-level lineage from Views and Explores Default: True |
extract_embed_urls boolean | Produce URLs used to render Looker Explores as Previews inside of DataHub UI. Embeds must be enabled inside of Looker to use this feature. Default: True |
extract_independent_looks boolean | Extract looks which are not part of any Dashboard. To enable this flag the stateful_ingestion should also be enabled. Default: False |
extract_owners boolean | When enabled, extracts ownership from Looker directly. When disabled, ownership is left empty for dashboards and charts. Default: True |
extract_usage_history boolean | Whether to ingest usage statistics for dashboards. Setting this to True will query looker system activity explores to fetch historical dashboard usage. Default: True |
extract_usage_history_for_interval string | Used only if extract_usage_history is set to True. Interval to extract looker dashboard usage history for. See https://docs.looker.com/reference/filter-expressions#date_and_time. Default: 30 days |
include_deleted boolean | Whether to include deleted dashboards and looks. Default: False |
max_threads integer | Max parallelism for Looker API calls. Defaults to cpuCount or 40 Default: 4 |
platform_instance string | The instance of the platform that all assets produced by this recipe belong to |
skip_personal_folders boolean | Whether to skip ingestion of dashboards in personal folders. Setting this to True will only ingest dashboards in the Shared folder space. Default: False |
strip_user_ids_from_email boolean | When enabled, converts Looker user emails of the form name@domain.com to urn:li:corpuser:name when assigning ownership Default: False |
tag_measures_and_dimensions boolean | When enabled, attaches tags to measures, dimensions and dimension groups to make them more discoverable. When disabled, adds this information to the description of the column. Default: True |
env string | The environment that all assets produced by this connector belong to Default: PROD |
chart_pattern AllowDenyPattern | Patterns for selecting chart ids that are to be included Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
chart_pattern.allow array(string) | |
chart_pattern.deny array(string) | |
chart_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
dashboard_pattern AllowDenyPattern | Patterns for selecting dashboard ids that are to be included Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
dashboard_pattern.allow array(string) | |
dashboard_pattern.deny array(string) | |
dashboard_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
explore_browse_pattern LookerNamingPattern | Pattern for providing browse paths to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name'] Default: {'pattern': '/{env}/{platform}/{project}/explores'... |
explore_browse_pattern.pattern ❓ string | |
explore_naming_pattern LookerNamingPattern | Pattern for providing dataset names to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name'] Default: {'pattern': '{model}.explore.{name}'} |
explore_naming_pattern.pattern ❓ string | |
transport_options TransportOptionsConfig | Populates the TransportOptions struct for looker client |
transport_options.headers ❓ map(str,string) | |
transport_options.timeout ❓ integer | |
view_browse_pattern LookerViewNamingPattern | Pattern for providing browse paths to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path'] Default: {'pattern': '/{env}/{platform}/{project}/views'} |
view_browse_pattern.pattern ❓ string | |
view_naming_pattern LookerViewNamingPattern | Pattern for providing dataset names to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path'] Default: {'pattern': '{project}.view.{name}'} |
view_naming_pattern.pattern ❓ string | |
stateful_ingestion StatefulStaleMetadataRemovalConfig | Base specialized config for Stateful Ingestion with stale metadata removal capability. |
stateful_ingestion.enabled boolean | The type of the ingestion state provider registered with datahub. Default: False |
stateful_ingestion.remove_stale_metadata boolean | Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled. Default: True |
The JSONSchema for this configuration is inlined below.
{
"title": "LookerDashboardSourceConfig",
"description": "Base configuration class for stateful ingestion for source configs to inherit from.",
"type": "object",
"properties": {
"env": {
"title": "Env",
"description": "The environment that all assets produced by this connector belong to",
"default": "PROD",
"type": "string"
},
"stateful_ingestion": {
"$ref": "#/definitions/StatefulStaleMetadataRemovalConfig"
},
"platform_instance": {
"title": "Platform Instance",
"description": "The instance of the platform that all assets produced by this recipe belong to",
"type": "string"
},
"explore_naming_pattern": {
"title": "Explore Naming Pattern",
"description": "Pattern for providing dataset names to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name']",
"default": {
"pattern": "{model}.explore.{name}"
},
"allOf": [
{
"$ref": "#/definitions/LookerNamingPattern"
}
]
},
"explore_browse_pattern": {
"title": "Explore Browse Pattern",
"description": "Pattern for providing browse paths to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name']",
"default": {
"pattern": "/{env}/{platform}/{project}/explores"
},
"allOf": [
{
"$ref": "#/definitions/LookerNamingPattern"
}
]
},
"view_naming_pattern": {
"title": "View Naming Pattern",
"description": "Pattern for providing dataset names to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path']",
"default": {
"pattern": "{project}.view.{name}"
},
"allOf": [
{
"$ref": "#/definitions/LookerViewNamingPattern"
}
]
},
"view_browse_pattern": {
"title": "View Browse Pattern",
"description": "Pattern for providing browse paths to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path']",
"default": {
"pattern": "/{env}/{platform}/{project}/views"
},
"allOf": [
{
"$ref": "#/definitions/LookerViewNamingPattern"
}
]
},
"tag_measures_and_dimensions": {
"title": "Tag Measures And Dimensions",
"description": "When enabled, attaches tags to measures, dimensions and dimension groups to make them more discoverable. When disabled, adds this information to the description of the column.",
"default": true,
"type": "boolean"
},
"extract_column_level_lineage": {
"title": "Extract Column Level Lineage",
"description": "When enabled, extracts column-level lineage from Views and Explores",
"default": true,
"type": "boolean"
},
"client_id": {
"title": "Client Id",
"description": "Looker API client id.",
"type": "string"
},
"client_secret": {
"title": "Client Secret",
"description": "Looker API client secret.",
"type": "string"
},
"base_url": {
"title": "Base Url",
"description": "Url to your Looker instance: `https://company.looker.com:19999` or `https://looker.company.com`, or similar. Used for making API calls to Looker and constructing clickable dashboard and chart urls.",
"type": "string"
},
"transport_options": {
"title": "Transport Options",
"description": "Populates the [TransportOptions](https://github.com/looker-open-source/sdk-codegen/blob/94d6047a0d52912ac082eb91616c1e7c379ab262/python/looker_sdk/rtl/transport.py#L70) struct for looker client",
"allOf": [
{
"$ref": "#/definitions/TransportOptionsConfig"
}
]
},
"dashboard_pattern": {
"title": "Dashboard Pattern",
"description": "Patterns for selecting dashboard ids that are to be included",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"chart_pattern": {
"title": "Chart Pattern",
"description": "Patterns for selecting chart ids that are to be included",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"include_deleted": {
"title": "Include Deleted",
"description": "Whether to include deleted dashboards and looks.",
"default": false,
"type": "boolean"
},
"extract_owners": {
"title": "Extract Owners",
"description": "When enabled, extracts ownership from Looker directly. When disabled, ownership is left empty for dashboards and charts.",
"default": true,
"type": "boolean"
},
"strip_user_ids_from_email": {
"title": "Strip User Ids From Email",
"description": "When enabled, converts Looker user emails of the form name@domain.com to urn:li:corpuser:name when assigning ownership",
"default": false,
"type": "boolean"
},
"skip_personal_folders": {
"title": "Skip Personal Folders",
"description": "Whether to skip ingestion of dashboards in personal folders. Setting this to True will only ingest dashboards in the Shared folder space.",
"default": false,
"type": "boolean"
},
"max_threads": {
"title": "Max Threads",
"description": "Max parallelism for Looker API calls. Defaults to cpuCount or 40",
"default": 4,
"type": "integer"
},
"external_base_url": {
"title": "External Base Url",
"description": "Optional URL to use when constructing external URLs to Looker if the `base_url` is not the correct one to use. For example, `https://looker-public.company.com`. If not provided, the external base URL will default to `base_url`.",
"type": "string"
},
"extract_usage_history": {
"title": "Extract Usage History",
"description": "Whether to ingest usage statistics for dashboards. Setting this to True will query looker system activity explores to fetch historical dashboard usage.",
"default": true,
"type": "boolean"
},
"extract_usage_history_for_interval": {
"title": "Extract Usage History For Interval",
"description": "Used only if extract_usage_history is set to True. Interval to extract looker dashboard usage history for. See https://docs.looker.com/reference/filter-expressions#date_and_time.",
"default": "30 days",
"type": "string"
},
"extract_embed_urls": {
"title": "Extract Embed Urls",
"description": "Produce URLs used to render Looker Explores as Previews inside of DataHub UI. Embeds must be enabled inside of Looker to use this feature.",
"default": true,
"type": "boolean"
},
"extract_independent_looks": {
"title": "Extract Independent Looks",
"description": "Extract looks which are not part of any Dashboard. To enable this flag the stateful_ingestion should also be enabled.",
"default": false,
"type": "boolean"
},
"emit_used_explores_only": {
"title": "Emit Used Explores Only",
"description": "When enabled, only explores that are used by a Dashboard/Look will be ingested.",
"default": true,
"type": "boolean"
}
},
"required": [
"client_id",
"client_secret",
"base_url"
],
"additionalProperties": false,
"definitions": {
"DynamicTypedStateProviderConfig": {
"title": "DynamicTypedStateProviderConfig",
"type": "object",
"properties": {
"type": {
"title": "Type",
"description": "The type of the state provider to use. For DataHub use `datahub`",
"type": "string"
},
"config": {
"title": "Config",
"description": "The configuration required for initializing the state provider. Default: The datahub_api config if set at pipeline level. Otherwise, the default DatahubClientConfig. See the defaults (https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/src/datahub/ingestion/graph/client.py#L19).",
"default": {},
"type": "object"
}
},
"required": [
"type"
],
"additionalProperties": false
},
"StatefulStaleMetadataRemovalConfig": {
"title": "StatefulStaleMetadataRemovalConfig",
"description": "Base specialized config for Stateful Ingestion with stale metadata removal capability.",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "The type of the ingestion state provider registered with datahub.",
"default": false,
"type": "boolean"
},
"remove_stale_metadata": {
"title": "Remove Stale Metadata",
"description": "Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"LookerNamingPattern": {
"title": "LookerNamingPattern",
"type": "object",
"properties": {
"pattern": {
"title": "Pattern",
"type": "string"
}
},
"required": [
"pattern"
],
"additionalProperties": false
},
"LookerViewNamingPattern": {
"title": "LookerViewNamingPattern",
"type": "object",
"properties": {
"pattern": {
"title": "Pattern",
"type": "string"
}
},
"required": [
"pattern"
],
"additionalProperties": false
},
"TransportOptionsConfig": {
"title": "TransportOptionsConfig",
"type": "object",
"properties": {
"timeout": {
"title": "Timeout",
"type": "integer"
},
"headers": {
"title": "Headers",
"type": "object",
"additionalProperties": {
"type": "string"
}
}
},
"required": [
"timeout",
"headers"
],
"additionalProperties": false
},
"AllowDenyPattern": {
"title": "AllowDenyPattern",
"description": "A class to store allow deny regexes",
"type": "object",
"properties": {
"allow": {
"title": "Allow",
"description": "List of regex patterns to include in ingestion",
"default": [
".*"
],
"type": "array",
"items": {
"type": "string"
}
},
"deny": {
"title": "Deny",
"description": "List of regex patterns to exclude from ingestion.",
"default": [],
"type": "array",
"items": {
"type": "string"
}
},
"ignoreCase": {
"title": "Ignorecase",
"description": "Whether to ignore case sensitivity during pattern matching.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
}
}
}
Code Coordinates
- Class Name:
datahub.ingestion.source.looker.looker_source.LookerDashboardSource - Browse on GitHub
Module lookml
Important Capabilities
| Capability | Status | Notes |
|---|---|---|
| Column-level Lineage | ✅ | Enabled by default, configured using extract_column_level_lineage |
| Detect Deleted Entities | ✅ | Optionally enabled via stateful_ingestion.remove_stale_metadata |
| Platform Instance | ✅ | Use the platform_instance and connection_to_platform_map fields |
| Table-Level Lineage | ✅ | Supported by default |
This plugin extracts the following:
- LookML views from model files in a project
- Name, upstream table names, metadata for dimensions, measures, and dimension groups attached as tags
- If API integration is enabled (recommended), resolves table and view names by calling the Looker API, otherwise supports offline resolution of these names.
To get complete Looker metadata integration (including Looker dashboards and charts and lineage to the underlying Looker views, you must ALSO use the looker source module.
Prerequisites
[Recommended] Create a GitHub Deploy Key
To use LookML ingestion through the UI, or automate github checkout through the cli, you must set up a GitHub deploy key for your Looker GitHub repository. Read this document for how to set up deploy keys for your Looker git repo.
In a nutshell, there are three steps:
Generate a private-public ssh key pair. This will typically generate two files, e.g. looker_datahub_deploy_key (this is the private key) and looker_datahub_deploy_key.pub (this is the public key). Do not add a passphrase.
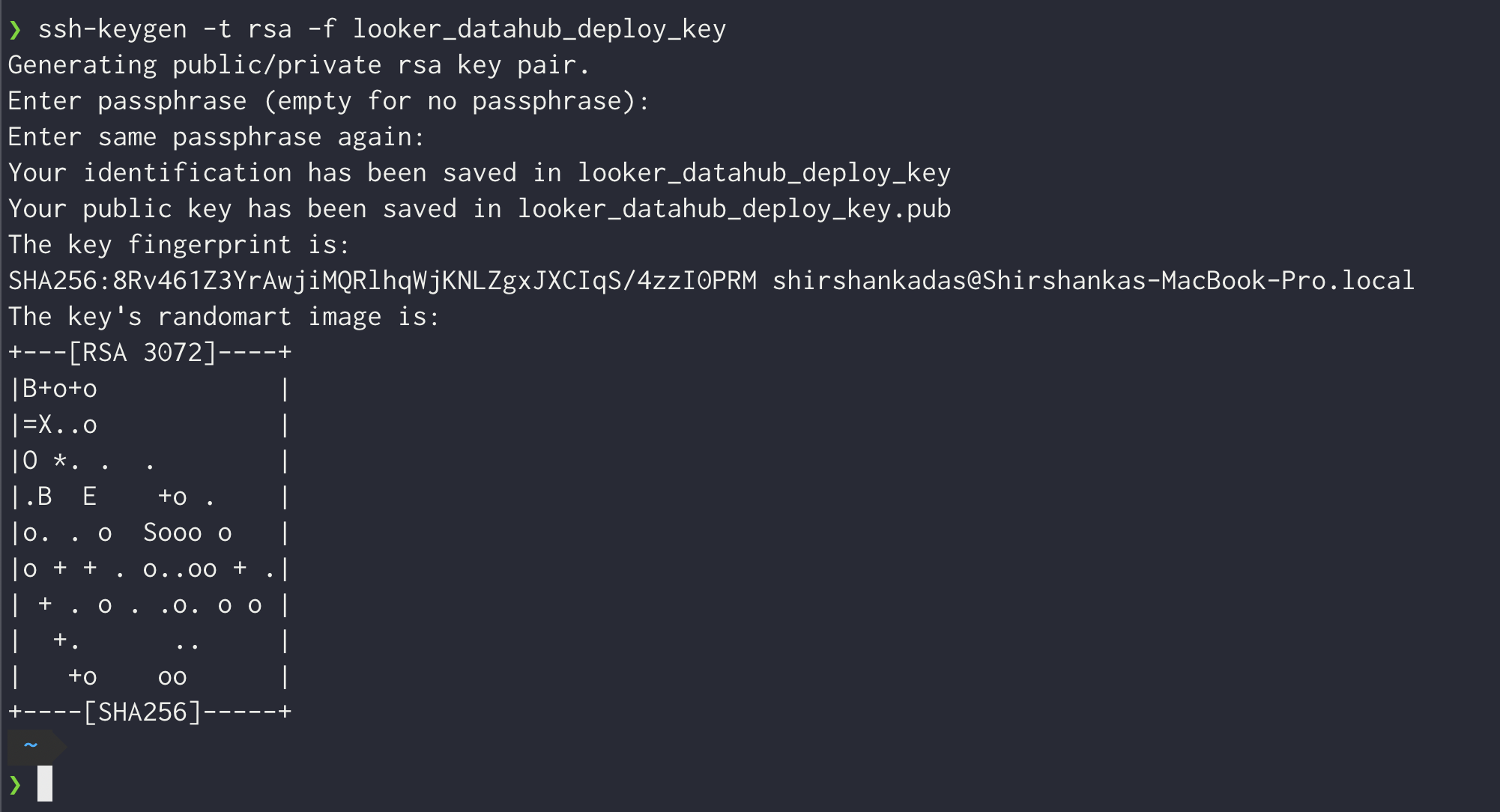
Add the public key to your Looker git repo as a deploy key with read access (no need to provision write access). Follow the guide here for that.
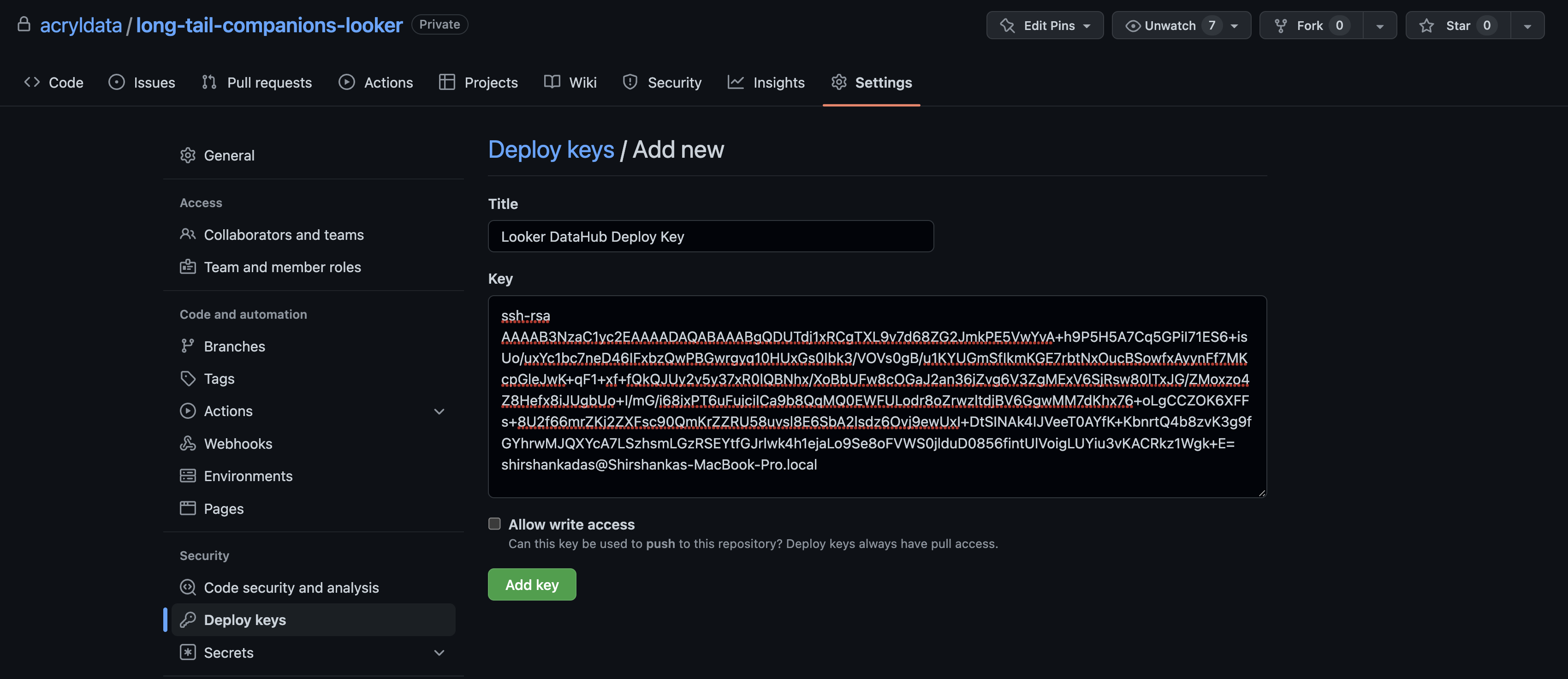
Make note of the private key file, you will need to paste the contents of the file into the GitHub Deploy Key field later while setting up ingestion using the UI.
Setup your connection mapping
The connection mapping enables DataHub to accurately generate lineage to your upstream warehouse. It maps Looker connection names to the platform and database that they're pointing to.
There's two ways to configure this:
- Provide Looker admin API credentials, and we'll automatically map lineage correctly. Details on how to do this are below.
- Manually populate the
connection_to_platform_mapandproject_nameconfiguration fields. See the starter recipe for an example of what this should look like.
[Optional] Create an API key with admin privileges
See the Looker authentication docs for the steps to create a client ID and secret. You need to ensure that the API key is attached to a user that has Admin privileges.
If you don't want to provide admin API credentials, you can manually populate the connection_to_platform_map and project_name in the ingestion configuration.
Ingestion Options
You have 3 options for controlling where your ingestion of LookML is run.
- The DataHub UI (recommended for the easiest out-of-the-box experience)
- As a GitHub Action (recommended to ensure that you have the freshest metadata pushed on change)
- Using the CLI (scheduled via an orchestrator like Airflow)
Read on to learn more about these options.
UI-based Ingestion [Recommended for ease of use]
To ingest LookML metadata through the UI, you must set up a GitHub deploy key using the instructions in the section above. Once that is complete, you can follow the on-screen instructions to set up a LookML source using the Ingestion page. The following video shows you how to ingest LookML metadata through the UI and find the relevant information from your Looker account.
GitHub Action based Ingestion [Recommended for push-based integration]
You can set up ingestion using a GitHub Action to push metadata whenever your main Looker GitHub repo changes. The following sample GitHub action file can be modified to emit LookML metadata whenever there is a change to your repository. This ensures that metadata is already fresh and up to date.
Sample GitHub Action
Drop this file into your .github/workflows directory inside your Looker GitHub repo.
You need to set up the following secrets in your GitHub repository to get this workflow to work:
- DATAHUB_GMS_HOST: The endpoint where your DataHub host is running
- DATAHUB_TOKEN: An authentication token provisioned for DataHub ingestion
- LOOKER_BASE_URL: The base url where your Looker assets are hosted (e.g. https://acryl.cloud.looker.com)
- LOOKER_CLIENT_ID: A provisioned Looker Client ID
- LOOKER_CLIENT_SECRET: A provisioned Looker Client Secret
name: lookml metadata upload
on:
# Note that this action only runs on pushes to your main branch. If you want to also
# run on pull requests, we'd recommend running datahub ingest with the `--dry-run` flag.
push:
branches:
- main
release:
types: [published, edited]
workflow_dispatch:
jobs:
lookml-metadata-upload:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-python@v4
with:
python-version: "3.10"
- name: Run LookML ingestion
run: |
pip install 'acryl-datahub[lookml,datahub-rest]'
cat << EOF > lookml_ingestion.yml
# LookML ingestion configuration.
# This is a full ingestion recipe, and supports all config options that the LookML source supports.
source:
type: "lookml"
config:
base_folder: ${{ github.workspace }}
parse_table_names_from_sql: true
github_info:
repo: ${{ github.repository }}
branch: ${{ github.ref }}
# Options
#connection_to_platform_map:
# connection-name:
# platform: platform-name (e.g. snowflake)
# default_db: default-db-name (e.g. DEMO_PIPELINE)
api:
client_id: ${LOOKER_CLIENT_ID}
client_secret: ${LOOKER_CLIENT_SECRET}
base_url: ${LOOKER_BASE_URL}
sink:
type: datahub-rest
config:
server: ${DATAHUB_GMS_URL}
token: ${DATAHUB_GMS_TOKEN}
EOF
datahub ingest -c lookml_ingestion.yml
env:
DATAHUB_GMS_URL: ${{ secrets.DATAHUB_GMS_URL }}
DATAHUB_GMS_TOKEN: ${{ secrets.DATAHUB_GMS_TOKEN }}
LOOKER_BASE_URL: ${{ secrets.LOOKER_BASE_URL }}
LOOKER_CLIENT_ID: ${{ secrets.LOOKER_CLIENT_ID }}
LOOKER_CLIENT_SECRET: ${{ secrets.LOOKER_CLIENT_SECRET }}
If you want to ingest lookml using the datahub cli directly, read on for instructions and configuration details.
CLI based Ingestion
Install the Plugin
pip install 'acryl-datahub[lookml]'
Starter Recipe
Check out the following recipe to get started with ingestion! See below for full configuration options.
For general pointers on writing and running a recipe, see our main recipe guide.
source:
type: "lookml"
config:
# GitHub Coordinates: Used to check out the repo locally and add github links on the dataset's entity page.
github_info:
repo: org/repo-name
deploy_key_file: ${LOOKER_DEPLOY_KEY_FILE} # file containing the private ssh key for a deploy key for the looker git repo
# Coordinates
# base_folder: /path/to/model/files ## Optional if you are not able to provide a GitHub deploy key
# Options
api:
# Coordinates for your looker instance
base_url: "https://YOUR_INSTANCE.cloud.looker.com"
# Credentials for your Looker connection (https://docs.looker.com/reference/api-and-integration/api-auth)
client_id: ${LOOKER_CLIENT_ID}
client_secret: ${LOOKER_CLIENT_SECRET}
# Alternative to API section above if you want a purely file-based ingestion with no api calls to Looker or if you want to provide platform_instance ids for your connections
# project_name: PROJECT_NAME # See (https://docs.looker.com/data-modeling/getting-started/how-project-works) to understand what is your project name
# connection_to_platform_map:
# connection_name_1:
# platform: snowflake # bigquery, hive, etc
# default_db: DEFAULT_DATABASE. # the default database configured for this connection
# default_schema: DEFAULT_SCHEMA # the default schema configured for this connection
# platform_instance: snow_warehouse # optional
# platform_env: PROD # optional
# connection_name_2:
# platform: bigquery # snowflake, hive, etc
# default_db: DEFAULT_DATABASE. # the default database configured for this connection
# default_schema: DEFAULT_SCHEMA # the default schema configured for this connection
# platform_instance: bq_warehouse # optional
# platform_env: DEV # optional
# Default sink is datahub-rest and doesn't need to be configured
# See https://datahubproject.io/docs/metadata-ingestion/sink_docs/datahub for customization options
Config Details
- Options
- Schema
Note that a . is used to denote nested fields in the YAML recipe.
| Field | Description |
|---|---|
base_folder string(directory-path) | Required if not providing github configuration and deploy keys. A pointer to a local directory (accessible to the ingestion system) where the root of the LookML repo has been checked out (typically via a git clone). This is typically the root folder where the *.model.lkml and *.view.lkml files are stored. e.g. If you have checked out your LookML repo under /Users/jdoe/workspace/my-lookml-repo, then set base_folder to /Users/jdoe/workspace/my-lookml-repo. |
emit_reachable_views_only boolean | When enabled, only views that are reachable from explores defined in the model files are emitted Default: True |
extract_column_level_lineage boolean | When enabled, extracts column-level lineage from Views and Explores Default: True |
max_file_snippet_length integer | When extracting the view definition from a lookml file, the maximum number of characters to extract. Default: 512000 |
parse_table_names_from_sql boolean | See note below. Default: False |
platform_instance string | The instance of the platform that all assets produced by this recipe belong to |
populate_sql_logic_for_missing_descriptions boolean | When enabled, field descriptions will include the sql logic for computed fields if descriptions are missing Default: False |
process_isolation_for_sql_parsing boolean | When enabled, sql parsing will be executed in a separate process to prevent memory leaks. Default: False |
process_refinements boolean | When enabled, looker refinement will be processed to adapt an existing view. Default: False |
project_name string | Required if you don't specify the api section. The project name within which all the model files live. See (https://docs.looker.com/data-modeling/getting-started/how-project-works) to understand what the Looker project name should be. The simplest way to see your projects is to click on Develop followed by Manage LookML Projects in the Looker application. |
sql_parser string | See note below. Default: datahub.utilities.sql_parser.DefaultSQLParser |
tag_measures_and_dimensions boolean | When enabled, attaches tags to measures, dimensions and dimension groups to make them more discoverable. When disabled, adds this information to the description of the column. Default: True |
env string | The environment that all assets produced by this connector belong to Default: PROD |
api LookerAPIConfig | |
api.base_url ❓ string | Url to your Looker instance: https://company.looker.com:19999 or https://looker.company.com, or similar. Used for making API calls to Looker and constructing clickable dashboard and chart urls. |
api.client_id ❓ string | Looker API client id. |
api.client_secret ❓ string | Looker API client secret. |
api.transport_options TransportOptionsConfig | Populates the TransportOptions struct for looker client |
api.transport_options.headers ❓ map(str,string) | |
api.transport_options.timeout ❓ integer | |
connection_to_platform_map map(str,LookerConnectionDefinition) | |
connection_to_platform_map. key.platform ❓string | |
connection_to_platform_map. key.default_db ❓string | |
connection_to_platform_map. key.default_schemastring | |
connection_to_platform_map. key.platform_envstring | The environment that the platform is located in. Leaving this empty will inherit defaults from the top level Looker configuration |
connection_to_platform_map. key.platform_instancestring | |
explore_browse_pattern LookerNamingPattern | Pattern for providing browse paths to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name'] Default: {'pattern': '/{env}/{platform}/{project}/explores'... |
explore_browse_pattern.pattern ❓ string | |
explore_naming_pattern LookerNamingPattern | Pattern for providing dataset names to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name'] Default: {'pattern': '{model}.explore.{name}'} |
explore_naming_pattern.pattern ❓ string | |
git_info GitInfo | Reference to your git location. If present, supplies handy links to your lookml on the dataset entity page. |
git_info.repo ❓ string | Name of your Git repo e.g. https://github.com/datahub-project/datahub or https://gitlab.com/gitlab-org/gitlab. If organization/repo is provided, we assume it is a GitHub repo. |
git_info.branch string | Branch on which your files live by default. Typically main or master. This can also be a commit hash. Default: main |
git_info.deploy_key string(password) | A private key that contains an ssh key that has been configured as a deploy key for this repository. See deploy_key_file if you want to use a file that contains this key. |
git_info.deploy_key_file string(file-path) | A private key file that contains an ssh key that has been configured as a deploy key for this repository. Use a file where possible, else see deploy_key for a config field that accepts a raw string. We expect the key not have a passphrase. |
git_info.repo_ssh_locator string | The url to call git clone on. We infer this for github and gitlab repos, but it is required for other hosts. |
git_info.url_template string | Template for generating a URL to a file in the repo e.g. '{repo_url}/blob/{branch}/{file_path}'. We can infer this for GitHub and GitLab repos, and it is otherwise required.It supports the following variables: {repo_url}, {branch}, {file_path} |
model_pattern AllowDenyPattern | List of regex patterns for LookML models to include in the extraction. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
model_pattern.allow array(string) | |
model_pattern.deny array(string) | |
model_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
project_dependencies One of map(str,union)(directory-path), map(str,union) | |
project_dependencies. key.repo ❓string | Name of your Git repo e.g. https://github.com/datahub-project/datahub or https://gitlab.com/gitlab-org/gitlab. If organization/repo is provided, we assume it is a GitHub repo. |
project_dependencies. key.branchstring | Branch on which your files live by default. Typically main or master. This can also be a commit hash. Default: main |
project_dependencies. key.deploy_keystring(password) | A private key that contains an ssh key that has been configured as a deploy key for this repository. See deploy_key_file if you want to use a file that contains this key. |
project_dependencies. key.deploy_key_filestring(file-path) | A private key file that contains an ssh key that has been configured as a deploy key for this repository. Use a file where possible, else see deploy_key for a config field that accepts a raw string. We expect the key not have a passphrase. |
project_dependencies. key.repo_ssh_locatorstring | The url to call git clone on. We infer this for github and gitlab repos, but it is required for other hosts. |
project_dependencies. key.url_templatestring | Template for generating a URL to a file in the repo e.g. '{repo_url}/blob/{branch}/{file_path}'. We can infer this for GitHub and GitLab repos, and it is otherwise required.It supports the following variables: {repo_url}, {branch}, {file_path} |
transport_options TransportOptionsConfig | Populates the TransportOptions struct for looker client |
transport_options.headers ❓ map(str,string) | |
transport_options.timeout ❓ integer | |
view_browse_pattern LookerViewNamingPattern | Pattern for providing browse paths to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path'] Default: {'pattern': '/{env}/{platform}/{project}/views'} |
view_browse_pattern.pattern ❓ string | |
view_naming_pattern LookerViewNamingPattern | Pattern for providing dataset names to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path'] Default: {'pattern': '{project}.view.{name}'} |
view_naming_pattern.pattern ❓ string | |
view_pattern AllowDenyPattern | List of regex patterns for LookML views to include in the extraction. Default: {'allow': ['.*'], 'deny': [], 'ignoreCase': True} |
view_pattern.allow array(string) | |
view_pattern.deny array(string) | |
view_pattern.ignoreCase boolean | Whether to ignore case sensitivity during pattern matching. Default: True |
stateful_ingestion StatefulStaleMetadataRemovalConfig | Base specialized config for Stateful Ingestion with stale metadata removal capability. |
stateful_ingestion.enabled boolean | The type of the ingestion state provider registered with datahub. Default: False |
stateful_ingestion.remove_stale_metadata boolean | Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled. Default: True |
The JSONSchema for this configuration is inlined below.
{
"title": "LookMLSourceConfig",
"description": "Base configuration class for stateful ingestion for source configs to inherit from.",
"type": "object",
"properties": {
"env": {
"title": "Env",
"description": "The environment that all assets produced by this connector belong to",
"default": "PROD",
"type": "string"
},
"stateful_ingestion": {
"$ref": "#/definitions/StatefulStaleMetadataRemovalConfig"
},
"platform_instance": {
"title": "Platform Instance",
"description": "The instance of the platform that all assets produced by this recipe belong to",
"type": "string"
},
"explore_naming_pattern": {
"title": "Explore Naming Pattern",
"description": "Pattern for providing dataset names to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name']",
"default": {
"pattern": "{model}.explore.{name}"
},
"allOf": [
{
"$ref": "#/definitions/LookerNamingPattern"
}
]
},
"explore_browse_pattern": {
"title": "Explore Browse Pattern",
"description": "Pattern for providing browse paths to explores. Allowed variables are ['platform', 'env', 'project', 'model', 'name']",
"default": {
"pattern": "/{env}/{platform}/{project}/explores"
},
"allOf": [
{
"$ref": "#/definitions/LookerNamingPattern"
}
]
},
"view_naming_pattern": {
"title": "View Naming Pattern",
"description": "Pattern for providing dataset names to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path']",
"default": {
"pattern": "{project}.view.{name}"
},
"allOf": [
{
"$ref": "#/definitions/LookerViewNamingPattern"
}
]
},
"view_browse_pattern": {
"title": "View Browse Pattern",
"description": "Pattern for providing browse paths to views. Allowed variables are ['platform', 'env', 'project', 'model', 'name', 'file_path']",
"default": {
"pattern": "/{env}/{platform}/{project}/views"
},
"allOf": [
{
"$ref": "#/definitions/LookerViewNamingPattern"
}
]
},
"tag_measures_and_dimensions": {
"title": "Tag Measures And Dimensions",
"description": "When enabled, attaches tags to measures, dimensions and dimension groups to make them more discoverable. When disabled, adds this information to the description of the column.",
"default": true,
"type": "boolean"
},
"extract_column_level_lineage": {
"title": "Extract Column Level Lineage",
"description": "When enabled, extracts column-level lineage from Views and Explores",
"default": true,
"type": "boolean"
},
"git_info": {
"title": "Git Info",
"description": "Reference to your git location. If present, supplies handy links to your lookml on the dataset entity page.",
"allOf": [
{
"$ref": "#/definitions/GitInfo"
}
]
},
"base_folder": {
"title": "Base Folder",
"description": "Required if not providing github configuration and deploy keys. A pointer to a local directory (accessible to the ingestion system) where the root of the LookML repo has been checked out (typically via a git clone). This is typically the root folder where the `*.model.lkml` and `*.view.lkml` files are stored. e.g. If you have checked out your LookML repo under `/Users/jdoe/workspace/my-lookml-repo`, then set `base_folder` to `/Users/jdoe/workspace/my-lookml-repo`.",
"format": "directory-path",
"type": "string"
},
"project_dependencies": {
"title": "Project Dependencies",
"description": "A map of project_name to local directory (accessible to the ingestion system) or Git credentials. Every local_dependencies or private remote_dependency listed in the main project's manifest.lkml file should have a corresponding entry here. If a deploy key is not provided, the ingestion system will use the same deploy key as the main project. ",
"default": {},
"type": "object",
"additionalProperties": {
"anyOf": [
{
"type": "string",
"format": "directory-path"
},
{
"$ref": "#/definitions/GitInfo"
}
]
}
},
"connection_to_platform_map": {
"title": "Connection To Platform Map",
"description": "A mapping of [Looker connection names](https://docs.looker.com/reference/model-params/connection-for-model) to DataHub platform, database, and schema values.",
"type": "object",
"additionalProperties": {
"$ref": "#/definitions/LookerConnectionDefinition"
}
},
"model_pattern": {
"title": "Model Pattern",
"description": "List of regex patterns for LookML models to include in the extraction.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"view_pattern": {
"title": "View Pattern",
"description": "List of regex patterns for LookML views to include in the extraction.",
"default": {
"allow": [
".*"
],
"deny": [],
"ignoreCase": true
},
"allOf": [
{
"$ref": "#/definitions/AllowDenyPattern"
}
]
},
"parse_table_names_from_sql": {
"title": "Parse Table Names From Sql",
"description": "See note below.",
"default": false,
"type": "boolean"
},
"sql_parser": {
"title": "Sql Parser",
"description": "See note below.",
"default": "datahub.utilities.sql_parser.DefaultSQLParser",
"type": "string"
},
"api": {
"$ref": "#/definitions/LookerAPIConfig"
},
"project_name": {
"title": "Project Name",
"description": "Required if you don't specify the `api` section. The project name within which all the model files live. See (https://docs.looker.com/data-modeling/getting-started/how-project-works) to understand what the Looker project name should be. The simplest way to see your projects is to click on `Develop` followed by `Manage LookML Projects` in the Looker application.",
"type": "string"
},
"transport_options": {
"title": "Transport Options",
"description": "Populates the [TransportOptions](https://github.com/looker-open-source/sdk-codegen/blob/94d6047a0d52912ac082eb91616c1e7c379ab262/python/looker_sdk/rtl/transport.py#L70) struct for looker client",
"allOf": [
{
"$ref": "#/definitions/TransportOptionsConfig"
}
]
},
"max_file_snippet_length": {
"title": "Max File Snippet Length",
"description": "When extracting the view definition from a lookml file, the maximum number of characters to extract.",
"default": 512000,
"type": "integer"
},
"emit_reachable_views_only": {
"title": "Emit Reachable Views Only",
"description": "When enabled, only views that are reachable from explores defined in the model files are emitted",
"default": true,
"type": "boolean"
},
"populate_sql_logic_for_missing_descriptions": {
"title": "Populate Sql Logic For Missing Descriptions",
"description": "When enabled, field descriptions will include the sql logic for computed fields if descriptions are missing",
"default": false,
"type": "boolean"
},
"process_isolation_for_sql_parsing": {
"title": "Process Isolation For Sql Parsing",
"description": "When enabled, sql parsing will be executed in a separate process to prevent memory leaks.",
"default": false,
"type": "boolean"
},
"process_refinements": {
"title": "Process Refinements",
"description": "When enabled, looker refinement will be processed to adapt an existing view.",
"default": false,
"type": "boolean"
}
},
"additionalProperties": false,
"definitions": {
"DynamicTypedStateProviderConfig": {
"title": "DynamicTypedStateProviderConfig",
"type": "object",
"properties": {
"type": {
"title": "Type",
"description": "The type of the state provider to use. For DataHub use `datahub`",
"type": "string"
},
"config": {
"title": "Config",
"description": "The configuration required for initializing the state provider. Default: The datahub_api config if set at pipeline level. Otherwise, the default DatahubClientConfig. See the defaults (https://github.com/datahub-project/datahub/blob/master/metadata-ingestion/src/datahub/ingestion/graph/client.py#L19).",
"default": {},
"type": "object"
}
},
"required": [
"type"
],
"additionalProperties": false
},
"StatefulStaleMetadataRemovalConfig": {
"title": "StatefulStaleMetadataRemovalConfig",
"description": "Base specialized config for Stateful Ingestion with stale metadata removal capability.",
"type": "object",
"properties": {
"enabled": {
"title": "Enabled",
"description": "The type of the ingestion state provider registered with datahub.",
"default": false,
"type": "boolean"
},
"remove_stale_metadata": {
"title": "Remove Stale Metadata",
"description": "Soft-deletes the entities present in the last successful run but missing in the current run with stateful_ingestion enabled.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"LookerNamingPattern": {
"title": "LookerNamingPattern",
"type": "object",
"properties": {
"pattern": {
"title": "Pattern",
"type": "string"
}
},
"required": [
"pattern"
],
"additionalProperties": false
},
"LookerViewNamingPattern": {
"title": "LookerViewNamingPattern",
"type": "object",
"properties": {
"pattern": {
"title": "Pattern",
"type": "string"
}
},
"required": [
"pattern"
],
"additionalProperties": false
},
"GitInfo": {
"title": "GitInfo",
"description": "A reference to a Git repository, including a deploy key that can be used to clone it.",
"type": "object",
"properties": {
"repo": {
"title": "Repo",
"description": "Name of your Git repo e.g. https://github.com/datahub-project/datahub or https://gitlab.com/gitlab-org/gitlab. If organization/repo is provided, we assume it is a GitHub repo.",
"type": "string"
},
"branch": {
"title": "Branch",
"description": "Branch on which your files live by default. Typically main or master. This can also be a commit hash.",
"default": "main",
"type": "string"
},
"url_template": {
"title": "Url Template",
"description": "Template for generating a URL to a file in the repo e.g. '{repo_url}/blob/{branch}/{file_path}'. We can infer this for GitHub and GitLab repos, and it is otherwise required.It supports the following variables: {repo_url}, {branch}, {file_path}",
"type": "string"
},
"deploy_key_file": {
"title": "Deploy Key File",
"description": "A private key file that contains an ssh key that has been configured as a deploy key for this repository. Use a file where possible, else see deploy_key for a config field that accepts a raw string. We expect the key not have a passphrase.",
"format": "file-path",
"type": "string"
},
"deploy_key": {
"title": "Deploy Key",
"description": "A private key that contains an ssh key that has been configured as a deploy key for this repository. See deploy_key_file if you want to use a file that contains this key.",
"type": "string",
"writeOnly": true,
"format": "password"
},
"repo_ssh_locator": {
"title": "Repo Ssh Locator",
"description": "The url to call `git clone` on. We infer this for github and gitlab repos, but it is required for other hosts.",
"type": "string"
}
},
"required": [
"repo"
],
"additionalProperties": false
},
"LookerConnectionDefinition": {
"title": "LookerConnectionDefinition",
"type": "object",
"properties": {
"platform": {
"title": "Platform",
"type": "string"
},
"default_db": {
"title": "Default Db",
"type": "string"
},
"default_schema": {
"title": "Default Schema",
"type": "string"
},
"platform_instance": {
"title": "Platform Instance",
"type": "string"
},
"platform_env": {
"title": "Platform Env",
"description": "The environment that the platform is located in. Leaving this empty will inherit defaults from the top level Looker configuration",
"type": "string"
}
},
"required": [
"platform",
"default_db"
],
"additionalProperties": false
},
"AllowDenyPattern": {
"title": "AllowDenyPattern",
"description": "A class to store allow deny regexes",
"type": "object",
"properties": {
"allow": {
"title": "Allow",
"description": "List of regex patterns to include in ingestion",
"default": [
".*"
],
"type": "array",
"items": {
"type": "string"
}
},
"deny": {
"title": "Deny",
"description": "List of regex patterns to exclude from ingestion.",
"default": [],
"type": "array",
"items": {
"type": "string"
}
},
"ignoreCase": {
"title": "Ignorecase",
"description": "Whether to ignore case sensitivity during pattern matching.",
"default": true,
"type": "boolean"
}
},
"additionalProperties": false
},
"TransportOptionsConfig": {
"title": "TransportOptionsConfig",
"type": "object",
"properties": {
"timeout": {
"title": "Timeout",
"type": "integer"
},
"headers": {
"title": "Headers",
"type": "object",
"additionalProperties": {
"type": "string"
}
}
},
"required": [
"timeout",
"headers"
],
"additionalProperties": false
},
"LookerAPIConfig": {
"title": "LookerAPIConfig",
"type": "object",
"properties": {
"client_id": {
"title": "Client Id",
"description": "Looker API client id.",
"type": "string"
},
"client_secret": {
"title": "Client Secret",
"description": "Looker API client secret.",
"type": "string"
},
"base_url": {
"title": "Base Url",
"description": "Url to your Looker instance: `https://company.looker.com:19999` or `https://looker.company.com`, or similar. Used for making API calls to Looker and constructing clickable dashboard and chart urls.",
"type": "string"
},
"transport_options": {
"title": "Transport Options",
"description": "Populates the [TransportOptions](https://github.com/looker-open-source/sdk-codegen/blob/94d6047a0d52912ac082eb91616c1e7c379ab262/python/looker_sdk/rtl/transport.py#L70) struct for looker client",
"allOf": [
{
"$ref": "#/definitions/TransportOptionsConfig"
}
]
}
},
"required": [
"client_id",
"client_secret",
"base_url"
],
"additionalProperties": false
}
}
}
Configuration Notes
The integration can use an SQL parser to try to parse the tables the views depends on.
This parsing is disabled by default, but can be enabled by setting parse_table_names_from_sql: True. The default parser is based on the sqllineage package.
As this package doesn't officially support all the SQL dialects that Looker supports, the result might not be correct. You can, however, implement a custom parser and take it into use by setting the sql_parser configuration value. A custom SQL parser must inherit from datahub.utilities.sql_parser.SQLParser
and must be made available to Datahub by ,for example, installing it. The configuration then needs to be set to module_name.ClassName of the parser.
Multi-Project LookML (Advanced)
Looker projects support organization as multiple git repos, with remote includes that can refer to projects that are stored in a different repo. If your Looker implementation uses multi-project setup, you can configure the LookML source to pull in metadata from your remote projects as well.
If you are using local or remote dependencies, you will see include directives in your lookml files that look like this:
include: "//e_flights/views/users.view.lkml"
include: "//e_commerce/public/orders.view.lkml"
Also, you will see projects that are being referred to listed in your manifest.lkml file. Something like this:
project_name: this_project
local_dependency: {
project: "my-remote-project"
}
remote_dependency: ga_360_block {
url: "https://github.com/llooker/google_ga360"
ref: "0bbbef5d8080e88ade2747230b7ed62418437c21"
}
To ingest Looker repositories that are including files defined in other projects, you will need to use the project_dependencies directive within the configuration section.
Consider the following scenario:
- Your primary project refers to a remote project called
my_remote_project - The remote project is homed in the GitHub repo
my_org/my_remote_project - You have provisioned a GitHub deploy key and stored the credential in the environment variable (or UI secret),
${MY_REMOTE_PROJECT_DEPLOY_KEY}
In this case, you can add this section to your recipe to activate multi-project LookML ingestion.
source:
type: lookml
config:
... other config variables
project_dependencies:
my_remote_project:
repo: my_org/my_remote_project
deploy_key: ${MY_REMOTE_PROJECT_DEPLOY_KEY}
Under the hood, DataHub will check out your remote repository using the provisioned deploy key, and use it to navigate includes that you have in the model files from your primary project.
If you have the remote project checked out locally, and do not need DataHub to clone the project for you, you can provide DataHub directly with the path to the project like the config snippet below:
source:
type: lookml
config:
... other config variables
project_dependencies:
my_remote_project: /path/to/local_git_clone_of_remote_project
This is not the same as ingesting the remote project as a primary Looker project because DataHub will not be processing the model files that might live in the remote project. If you want to additionally include the views accessible via the models in the remote project, create a second recipe where your remote project is the primary project.
Debugging LookML Parsing Errors
If you see messages like my_file.view.lkml': "failed to load view file: Unable to find a matching expression for '<literal>' on line 5" in the failure logs, it indicates a parsing error for the LookML file.
The first thing to check is that the Looker IDE can validate the file without issues. You can check this by clicking this "Validate LookML" button in the IDE when in development mode.
If that's not the issue, it might be because DataHub's parser, which is based on the joshtemple/lkml library, is slightly more strict than the official Looker parser. Note that there's currently only one known discrepancy between the two parsers, and it's related to using multiple colon characters when defining parameters.
To check if DataHub can parse your LookML file syntax, you can use the lkml CLI tool. If this raises an exception, DataHub will fail to parse the file.
pip install lkml
lkml path/to/my_file.view.lkml
Code Coordinates
- Class Name:
datahub.ingestion.source.looker.lookml_source.LookMLSource - Browse on GitHub
Questions
If you've got any questions on configuring ingestion for Looker, feel free to ping us on our Slack.